
Part 1, improving an A-level ecosystem with horizontal scaling.
The organizational archetypes of the Org Topologies™ map can be used to plot organization designs that we refer to as ecosystems. This article describes an A-type ecosystem for (software) product development, the prevalent dynamics in it, and the solutions to improve performance using Org Topologies™ mapping.
If you are unfamiliar with the Org Topologies™ approach, you can read this article to catch up and have a basic understanding of Org Topologies™.
Example of an A-type Ecosystem
The A-level ecosystem is a combination of organizational archetypes where the A-level archetype is most prominent. At the A-level, as per the Org Topologies™ map, the work is done by the teams at the feature level. This means that their Product Backlog contains features, rather than tasks or business initiatives. However, customers do not think about application features, they have a “job to be done”, a need to be met. For example, a user might need to find the best option to travel from A to B. We can help the user by offering a product that will allow them to select a mode of transport based on relevant selection criteria (time of itinerary, cost, scheduled departure or arrival times, etc). This product consists of a series of features: set selection criteria, search, show travel options, select travel options, see itinerary details, manage profile, price alerts, etc). In the A-level ecosystem, there will be one or more teams assigned to build and maintain (a set of) features. In our example, the A-level teams are of type A2, which means not all capabilities are available in the teams to deliver a Done product. They depend on other organizational elements for shipping value to the customer. In other words, to provide a fully operational solution to the customer, we need multiple organizational elements to collaborate. This is a common situation in software development groups.
In our example, this is an enterprise business analyst group (which can be mapped to archetype C0, an individual with a whole product focus). After decomposition, the feature-level work is further refined by the analyst group before the work is picked up by the A2-level teams. Each of the teams is responsible for building a certain feature(set). There is a travel team, travel feed-engine team, customer data team, and itineraries team. These teams work with Scrum. The analysts are not organized as a (Scrum) team. They are grouped into a department based on their expertise. (This is a Y1 archetype). After the features have been tested, we need an integration team to assemble the features into one working product, the user experience team will test the integrated product for consistency, and the performance and security team will need to verify the product before handing it off to the maintenance team for going live. These teams have a whole product focus but they have a single skill as they perform only a step of the complete product development process. Below is a visual representation (an Org Topologies™ mapping) of the ecosystem.
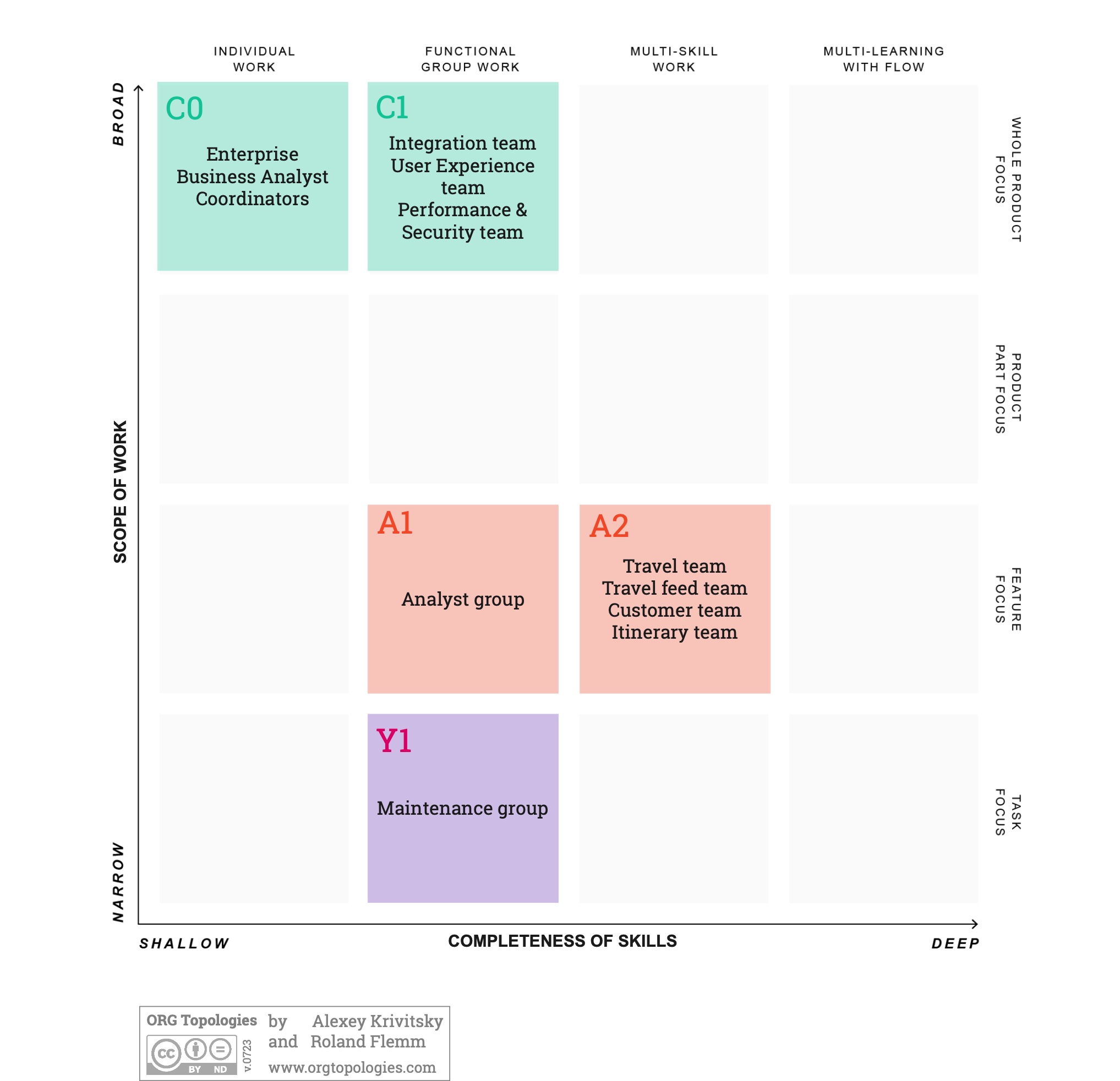
Dynamics of this Ecosystem
Each A2 team has its own Product Owner and Product Backlog. The specifications of the customer needs are prepared by the analysts and spread across multiple Product Backlogs. The development of features will be performed asynchronously. This is because each Product Owner can individually decide on priorities. Also, there are variations in team speed. And asynchrony is inevitable because the amount of work for each team varies. The Customer team might have little work creating a login screen and a customer profile page, while the Travel Feed team might take much more time to disclose information from a large number of external sources.
Another interesting observation is that teams will not stay idle after delivering the required functionality for a certain customer journey. They will remain busy by adding functionality to their feature that their Product Owner deems valuable (face recognition maybe?). Also, the team might propose to upgrade their code to the latest frameworks and software patterns. Strictly speaking, this does not necessarily add value from the customer's perspective, nor might this be beneficial for the other teams. Doing work that is not adding value at the whole product level is also known as ”local optimization”.
Before a working product can be shipped, the work has to pass through the C1 groups and maintenance department. There is a lot of information going back and forth (round-robin) between the elements of the ecosystem that needs to be coordinated. The dynamics can be summarized as follows:
-
Information scattered across many backlogs
-
Asynchronous dependencies
-
Local optimization
-
High-frequency round-robin of work
-
Need for coordination roles
Looking at the performance of this system, we see that there is low predictability on the delivery at the business initiative level (or customer need level). Also, we see that over time, there is a growing need for coordination due to the growing asynchronicity of the work. Transaction costs are increasing due to increasing lead times.
Resolving problems the fast way
The company’s leaders want to have clarity on the possible delivery dates of new initiatives. This is difficult due to the high number of handoffs, round robins for rework, and isolated feature focus of the teams. Which such an organizational design, the likeliness of not meeting anticipated delivery dates is high. Once this happens, a common procedure is for the leadership to summon the coordinators to report on possible causes for the delay and present plans for improvement. To speed up, it is not unlikely managers will propose to add more teams. However, there is ample evidence this does not work:
“Adding human resources to a late software project makes it later.”
This is Brooks’ Law which learns us that adding teams will make the system perform worse. As a result, managers will push harder on the teams, team members will get frustrated, and leadership will be aggravated because the increased cost of additional teams does not give better results. These dynamics might be familiar to you.
Resolving problems in a systemic way with horizontal scaling
We should address this problem by looking at how the elements of the whole ecosystem interact. Managers should not waste energy trying to optimize the existing system. They can invest their time and energy more wisely in understanding the system, discovering the root causes, and considering options to redesign the system.
All ecosystems are sticky. Its elements will try to stay in equilibrium and maintain the status quo, even when it is under pressure. How does this work? First of all, people want painless and fast solutions, as opposed to finding and implementing a deeper solution which will take more time and effort. Secondly, the coordinators will be tasked by higher management to improve the system. But what if the coordinators are a part of the problem? They will most likely not see themselves as a cause for the poor performance, as this implies self-sacrifice.
In our example, we see a large amount of dependencies between teams. This problem was addressed by appointing coordinators to handle them. But was that the right solution? Did we address the root causes for having dependencies? No, we did not, because the fix did not make the dependencies disappear. Instead, we institutionalized them by appointing dependency managers, aka coordinators.
We need to think deeper and look for a solution that results in a system without dependencies, or at least reduces the most important ones. For this, we must study how information flows go back and forth when developing a product. We need to understand why these information flows are a problem. We should start by looking at the dependencies of the A2-level teams because they are at the core of delivering customer value.
The analysts, A2 teams, integration, security and performance, and maintenance groups are tightly coupled. The information between the groups round robins at high frequency: A development team hands off their work to the integration group, they raise bugs that need to be fixed by the developers, and so on. This kind of dependency occurs often and is also known as “Reciprocal dependency”. We want to reduce them as much as we can. We don’t care too much about dependencies that only pop up every so often. After all, we do not want to optimize the org design for exceptions.
We need to contain the reciprocal dependencies inside a single team or (product) group. Possible solutions to achieve this are:
-
Existing team members learn the missing skill (obtain knowledge)
-
We give the mandate to the team to perform the missing skill (obtain permissions)
-
Automate and create a self-service solution (self-service, no-code/low-code solutions)
-
We add someone with the missing skill/knowledge to the team
-
We create new teams by mixing the existing single-skilled teams into teams that contain the reciprocal dependencies
The result:
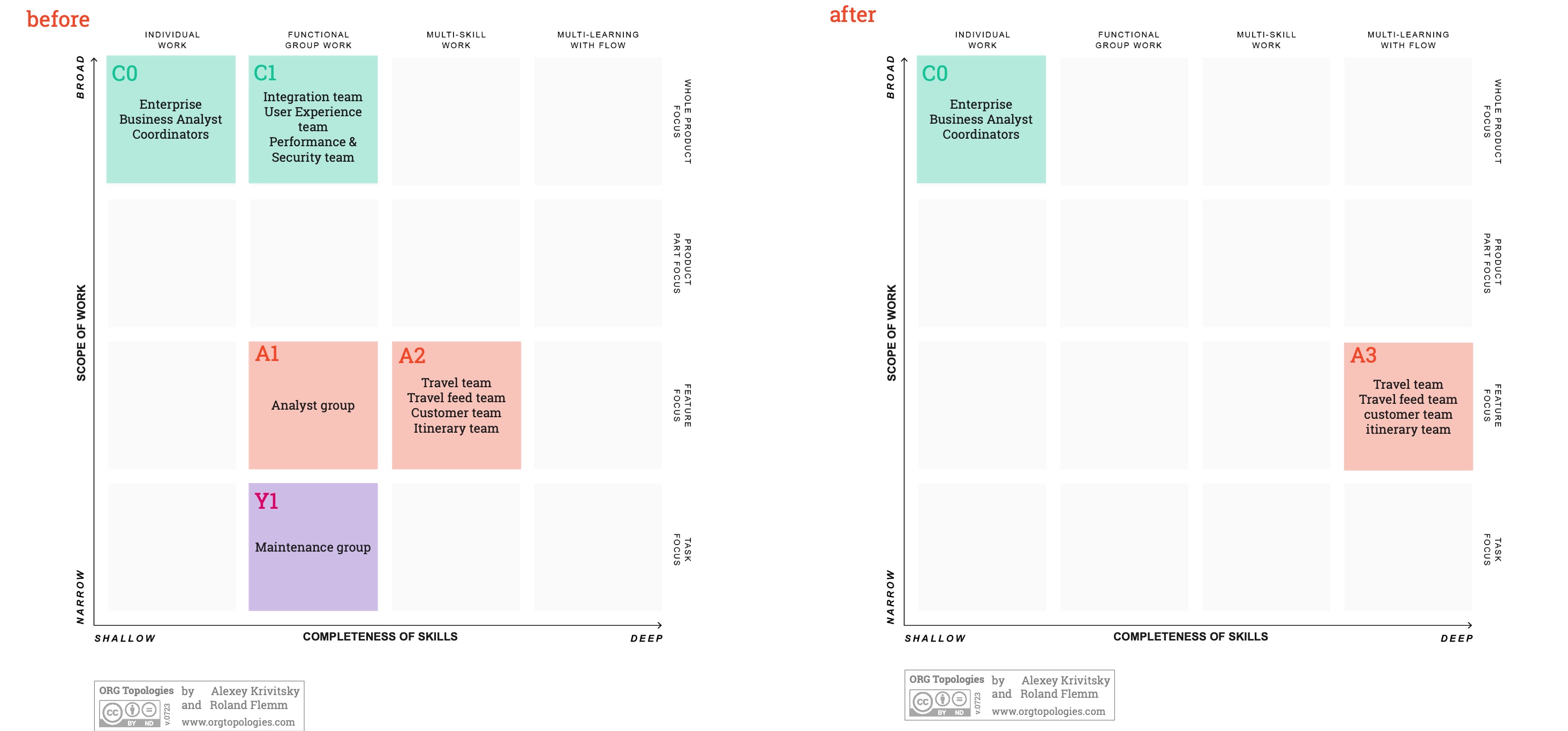
In the given example, we choose to change the organizational design by recreating teams that are better set up to deliver a Done increment every Sprint. This means that each A2 development team should be expanded with the missing skills to deliver a working product. . This will dissolve most of the other groups. By doing this, we will have contained a large number of unwanted dependencies in the teams. The teams will become A3-type teams (multi-learning with flow) and will lower the need for coordination drastically. After all, the teams do not work at the customer problem level.
Get Certified
In this article, we described a scenario for improving the org design using the Org Topologies™ map. If you want to learn more and build experience in understanding and designing agile ecosystems, consider signing up for our upcoming two-day Certified Org Topologies™ Practitioner (COTP level-1) classes.
© Alexey Krivitsky and Roland Flemm, 2023.